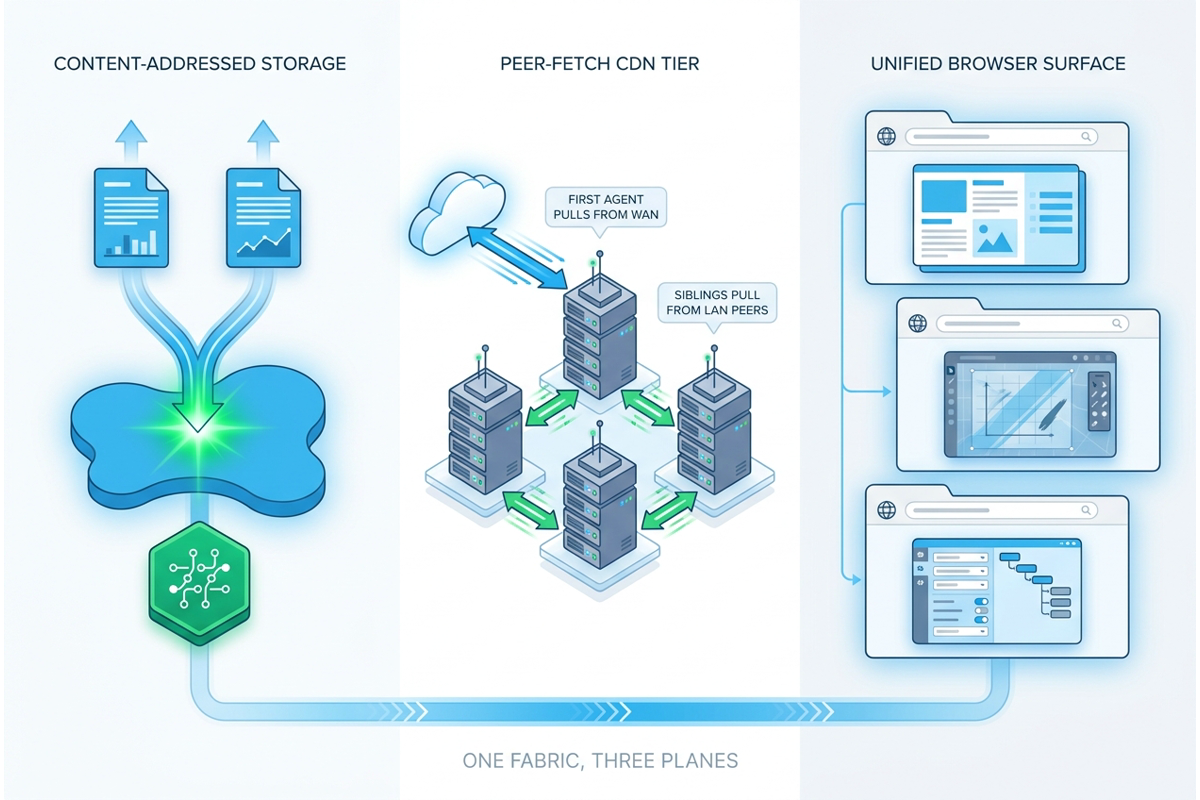
One document surface, not a different attachment widget per feature.
“Isn’t this just file storage with extra steps?”
That’s the skeptic’s question, and it’s a fair one. Most platforms in our category bolt on an “attachments” feature: an opaque JSON blob hanging off a workflow, a per-feature uploader, no dedup, no peer fetch, no typed contract. The platform’s documents page and the workflow node’s file picker disagree about what a document even is.
We did something different. The Unified Document System is one document fabric for the whole platform — content-addressed (deduplicated by hash), site-aware (cached on the on-premise Valdis™ agent that needs it, fetched peer-to-peer over the LAN rather than the WAN), RBAC-scoped, and consumed through a single typed binding contract that lets any workflow node declare the documents it uses.
Three accreted pains retired:
- Storage amplification. Path-addressed storage meant every upload — every copy of the same firmware image, every duplicate config archive — was a fresh file on disk. Fifty engineers uploading the same 1.2 GB image meant fifty physical copies.
- Bolt-on attachments. “Attached documents” used to live as an opaque JSON list inside the workflow graph — not a first-class, queryable, RBAC-aware relation.
- WAN re-pull. Fifty devices at one site needing the same firmware meant fifty WAN transfers.
Each of these maps directly to a real cost line on a real customer invoice. Let’s walk through how the substrate fixes them.
Capability 1 — Content-addressable storage
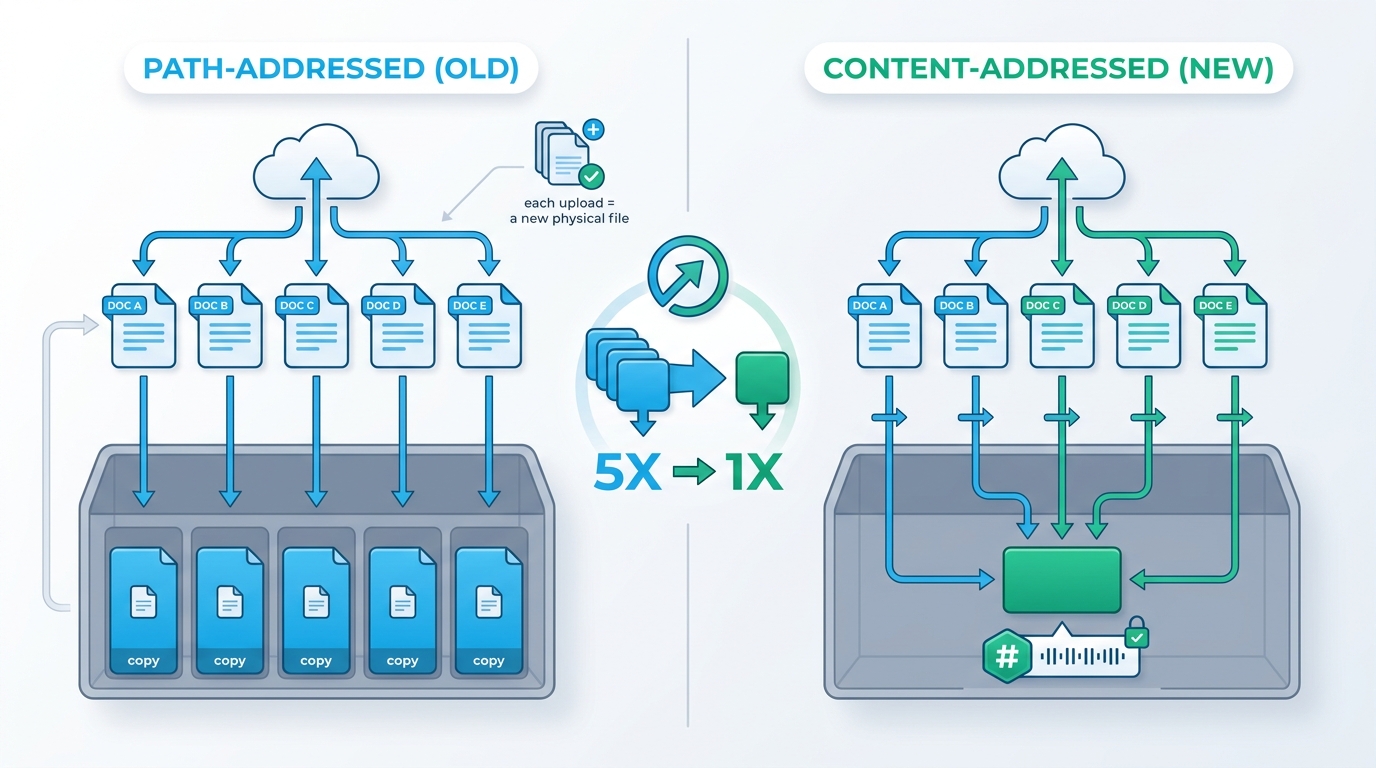 Identical bytes are stored once. The same upload twice is an INSERT … ON CONFLICT on the content hash — one row, one physical blob, two logical references.
Identical bytes are stored once. The same upload twice is an INSERT … ON CONFLICT on the content hash — one row, one physical blob, two logical references.
Old world (Epic 15 baseline): documents were stored at …/{org}/{year}/{month}/{uuid}/{filename}. The SHA-256 column existed, but only for integrity verification — never as an address or a dedup key. Identical bytes uploaded twice produced two physical files.
New world (Epic 62): documents are addressed by their content hash. Upload the same firmware image twice and the second upload is an INSERT … ON CONFLICT on the content hash — one row, one physical blob, two logical references.
The engineering details that matter:
- Dedup is transactional, garbage collection isn’t. The DB row delete and the reference-count decrement happen inside the same transaction. The on-disk file unlink is post-commit, with a compare-and-swap re-check — the unlink only runs if the refcount is still zero. This means a transient concurrent re-reference during a GC pass cannot leave you with a dangling row pointing at a deleted blob.
- Quota counts logical references, not unique post-dedup bytes. If org A and org B both upload the same firmware image, each org is billed for one document’s worth of quota. Cross-org dedup is invisible to billing — you don’t get a surprise refund and your neighbor doesn’t get a surprise charge.
- Cross-org dedup isolation is at the signal layer. Blobs are physically shared across orgs (SHA-256 is a global key — there is no per-tenant namespace). But the
dedup:true|falseresponse flag is computed per-org viaSELECT 1 FROM document WHERE org_id=$1 AND sha256=$2. So a cross-org hit reportsdedup:false— org B is never told that org A already holds the bytes. Shared physical store, isolated logical signal, isolated accounting.
What this means for you in practice: upload the same 4 GB Junos image to twenty workflows. You’re billed for twenty references but pay disk for one blob.
Capability 2 — The peer-fetch CDN tier
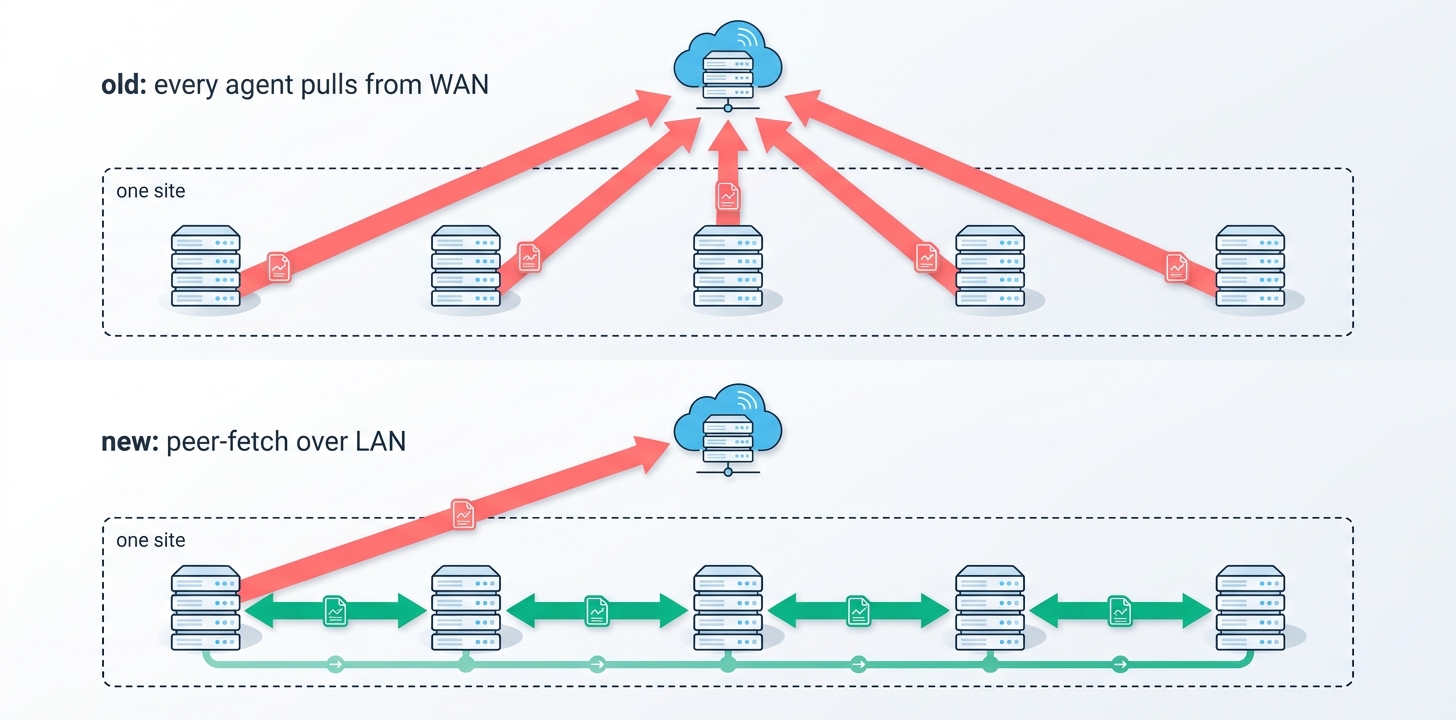 Same-site agents fetch from each other over the LAN. The first agent pulls from the backend; the rest share laterally.
Same-site agents fetch from each other over the LAN. The first agent pulls from the backend; the rest share laterally.
Now the WAN-saving piece. This is the one that matters most for multi-site operators.
Old behavior: every Valdis™ agent that needed a document pulled it from the backend over the WAN. Fifty agents at one site needing the same firmware image → fifty WAN transfers.
New behavior: an agent’s blob resolution order is:
- Local cache. Already on disk? Done.
- Peer-fetch from same-site sibling.
GET /cache/<sha256>over the LAN. First 200 OK wins. Order is shuffled per-request, bounded by an overall resolve timeout. - Backend ticketed download. Only if the site’s policy allows backend fallback.
- Fail loud. Never a silent fallback to “no document.”
So fifty agents at one site needing the same image → one WAN transfer (whichever agent gets it first), then forty-nine LAN transfers between siblings.
How peer authentication works without mTLS overhead
Peer-fetch could have been built on mutual TLS, with full PKI per-site, per-agent. We chose differently — and the reasoning matters because security-conscious buyers ask.
Peer-to-peer auth is an HMAC-SHA256 bearer token with canonical pipe-separated claims, rotated every 6 hours via the heartbeat. The receiving peer’s check is stateless — no per-request database read. It validates three things:
- The HMAC signature is well-formed and current.
- The token’s
agent_idmatches the request signer’s source IP (pinned via the heartbeat-cached peer list). - The token’s
organdsitematch the receiver’s own latest heartbeat-cached site-peers snapshot — so a stale cross-site token automatically fails as soon as either side’s heartbeat refreshes.
A serving peer re-hashes the blob from disk before streaming. A cache miss returns 404 immediately — a peer never proxies to the backend on a miss. No transitive trust. The peer is either holding the bytes you asked for or it’s not.
TLS handshake-layer pinning (Epic 73)
In Epic 73 (shipped 2026-05-23) we added cert verification and per-peer pin enforcement on top. The outbound peer-fetch now uses aiohttp.Fingerprint to validate the leaf cert at the TLS handshake layer. The non-obvious detail: on cert mismatch the connection closes before the HTTP request body — and therefore the rotating HMAC bearer — is sent. The bearer token is never exposed to a misidentified peer. A revoked or rotated peer cert kills the connection before any auth material crosses the wire.
This is what we mean by zero-trust at the agent fabric. The peer-fetch path is bounded by a stateless HMAC check, capped by a TLS-handshake-layer pin, and floored by an immediate-fail 404 on cache miss.
Capability 3 — The unified browser shell
Old surface: three separate UIs.
- The
/documentspage. - The canvas docs panel.
- The per-node file picker.
Three UIs, three opinions about what a document is, three RBAC code paths, three places to fix any bug.
New surface: UnifiedDocumentBrowser.jsx, one component, mounted in three contexts via a context prop (page / canvas / node-config). Same list, same search, same RBAC, same selection model. The component renders the right chrome for the context but the data plane underneath is identical.
Document references now live on individual nodes through the binding contract (next section), not as an opaque attachments list on the workflow graph. This means the question “which documents does this workflow depend on?” is a real query against a real relation, not a JSON-walk.
Capability 4 — The multi-node binding contract
This is the load-bearing engineering most “document attachments” features get wrong.
A binding is a typed, server-authoritative reference from a workflow node to a resource. The resource might be a CAS document, a backup, a Gitea-hosted Ansible playbook (which has no per-row UUID), or a parser template (NTC or custom). Four different id shapes, four different RBAC paths, one contract.
The load-bearing piece is the _resolveResource per-kind dispatcher — a switch over four resolvers handling these heterogeneous id shapes:
 Four resource kinds, four id shapes, four backing stores. One contract resolves them all — and collapses cross-org, nonexistent, and malformed-id failures to a byte-identical not_visible result.
Four resource kinds, four id shapes, four backing stores. One contract resolves them all — and collapses cross-org, nonexistent, and malformed-id failures to a byte-identical not_visible result.
Every resolver collapses three failure modes — cross-org, nonexistent, malformed id — to a byte-identical not_visible result. No existence oracle. You cannot distinguish “this document doesn’t exist” from “this document exists in another org you can’t see” from “your id is garbage.” Pinned by an 18/18 adversarial test suite including cross-type-swap and cross-org cases.
A cross-org attempt writes an audit row that deliberately omits the other org’s resource name. The audit trail records that an unauthorized access was attempted; it does not become a side-channel for inferring the existence or naming of another tenant’s resources.
Two-tab lossy-write detection
Concurrent edits in two browser tabs used to silently clobber each other. The binding contract now ships an optimistic-concurrency CAS UPDATE — if the version you read doesn’t match the version at write time, you get a 409 lossy_write_detected response, not a silent overwrite. You see a “this binding changed in another tab — refresh to merge” prompt. The data plane refuses to be the source of a quiet data loss.
What you can actually do with this, today
Three concrete operational stories we’ve watched customers run in beta:
Firmware staging. Upload a 4 GB Junos image once. Bind it to a workflow node that targets every Junos device at site A. The first agent at site A that runs the workflow pulls the blob from the backend. The next forty-nine devices in that workflow’s iterator find the blob on a same-site Valdis™ peer over the LAN. One WAN transfer, fifty deployments.
Config-archive dedup. Nightly config backups across 5,000 devices produce a lot of byte-identical configs. CAS dedup compresses that to one physical blob per content version. Storage growth tracks unique config changes, not backup counts.
Ansible playbook bindings. Bind a Gitea-hosted playbook (composite id, no UUID) to an Ansible node. The binding contract treats it identically to a CAS document for RBAC, audit, and lossy-write purposes — the workflow node doesn’t care that the underlying resource has a different id shape.
What this isn’t
We’re honest about two scoping notes that the deep-dive carries through.
The legacy store was not migrated. The Epic-15 path-addressed store and the new CAS store coexist permanently. “Documents” (legacy: folders, ACL, execution artifacts, bulk import) and “Device Files” (CAS: dedup, site-affinity, agent caching) are siblings solving different problems, not predecessor/successor. The old /api/documents/* routes still serve the legacy substrate; CAS is at /api/documents/cas/*. We considered a forklift migration and chose the lower-risk path. No-data-loss-by-design.
Epic 62’s “unified document experience” story (62-9) was reframed, not delivered as planned. During UX discovery we found three coupled epics’ worth of work hiding behind one story: Qdrant-ingestion-as-upload-destination, a typed binding contract across 5+ node types, and drag-drop-deploy. We split it into Epic 63 (63-1 shell + retirement, 63-2 binding contract, 63-3 upload+ingest). The “unified” experience landed in Epic 63, not Epic 62. We mention this here because honest scoping discipline is the same discipline that produced the architecture.
How to try it
If you’re on Regnor™ Cloud beta:
- Upload a file at
/documents/cas— try uploading the same file twice and observe thededup:truesignal on the second upload. - Bind that document to a workflow node via the unified browser (mounted in the node config panel).
- Run the workflow against a multi-device site. In your Valdis™ agent logs, watch the peer-fetch path light up — first agent pulls from backend, siblings pull from peer.
If you’re not on Regnor™ Cloud yet, start the beta.
What’s next on this surface
Three iterations in backlog or in flight:
- Drag-drop-deploy — drag a document from the browser onto a device on the topology canvas; the binding + deployment workflow are inferred from the document type.
- CAS as the substrate for Tavrin™ evidence storage — WORM-sealed (Write-Once, Read-Many — a SOC 2 / ISO 27001 / FedRAMP / PCI requirement for tamper-evident audit records) compliance evidence rows reference CAS-stored attestation bundles, so the same dedup + peer-fetch fabric carries audit evidence to its consumers.
- Per-site CAS quota and eviction policy — bound the agent-side cache size per site with a configurable LRU, so a long-running site with a hot working set doesn’t accumulate unbounded historical blobs.
Each of these layers on without re-litigating the substrate. Content-addressing made dedup free. Peer-fetch made WAN-pull optional. The binding contract made workflow-node-to-resource a real relation. New features inherit those guarantees.
Read more
- Previous in this series: Ask your network a question in plain English — and the LLM never touches your database.
- Previous in this series: Clone production into a lab — and rehearse every change before you ship it.
- Coming next: “Tavrin™ Auto-Dispatch — when the rule fires, the fix runs, and the evidence is WORM.”
Regnor™, Valdis™, and Tavrin™ are trademarks of AutomateNetOps (registration pending). Capabilities described in this article shipped in Epics 15, 62, and 63.
Tags: binding-contract, cas, cdn, content-addressable-storage, dedup, multi-site, on-premise, peer-fetch, regnor, tls-pinning, unified-document-system, valdis, zero-trust
Categories: Network Automation, Platform Engineering
Updated:
You may also enjoy
How Regnor™ Topology lets you query your network in plain English and rewind it through time — built so the LLM never touches your database and the past is h...

How Regnor™ Lab Designer turns a slice of real production into a runnable lab — drag-canvas, lossless YAML round-trip, Clone/Branch/Match from prod, and a pe...
About Me

Ready to Automate?
See how AutomateNetOps.AI can transform your network operations with zero-trust security.