The Vault Problem: Zero-Downtime Credential Sync Across Multi-Agent HA
It’s 02:00 on a Tuesday. Your on-premise automation agent reboots — kernel patch, OOM kill, container restart, doesn’t matter. A workflow scheduled for 02:05 dispatches against forty-seven core switches. The backend looks for an online agent in your org and finds none. The workflow queues. At 07:00 you wake up to a Slack alert: “nightly-backup-core-switches aborted: no online agent.”
Six hours of MTTR for a one-minute reboot.
The obvious fix is to add a second agent for high availability. So you do. agent-2 registers, comes online, the load balancer happily round-robins workflow runs to it. Until a workflow lands on agent-2 that needs a credential only agent-1 ever stored. The agent’s task receiver checks its local Vault, gets a miss, and emits a credential_unavailable message. The workflow fails after a 15-second wait.
Your “high availability” just gave you more failure surface, not less.
Welcome to the Vault problem.
What “Zero-Trust” Actually Costs You
If you’ve spent any time evaluating network automation tools, you’ve heard the phrase “credentials never leave your network” enough times that it’s lost meaning. Every vendor with a security page makes the claim. Most of them fudge it.
Here’s how we make it real in Regnor™: every on-premise agent ships with its own local HashiCorp Vault. SSH passwords, SNMP communities, API tokens — they all live behind the customer’s firewall, in a Vault instance the cloud control plane has no key material for. The cloud knows that credential UUID f3a1... exists. It does not know what f3a1... is.
That’s a defensible architecture for a single agent. The moment a customer wants two — for HA, for geographic distribution, for rolling updates — the architecture has to do something it never had to do before: get a credential from one agent’s Vault into another agent’s Vault, without the cloud control plane ever seeing it.
Most platforms in our space punt on this. They fall into one of two camps:
- “Centralize credentials in cloud.” Easy to engineer. Veto’d on day one by every security team in a regulated industry.
- “Run a single agent.” Easy to engineer. Veto’d on day one by every ops team that’s experienced a 02:00 reboot.
The interesting question is whether you can have both — zero-trust and zero-downtime — at the same time.
This article walks through how we did it, what’s novel about the design (a piece of which we filed as Patent 10 on April 25, 2026), and what the implementation actually looks like in shipped code.
The Three-Party Dance
Every credential sync in Regnor™ is a three-party choreography between a target agent, a peer agent, and the backend control plane.
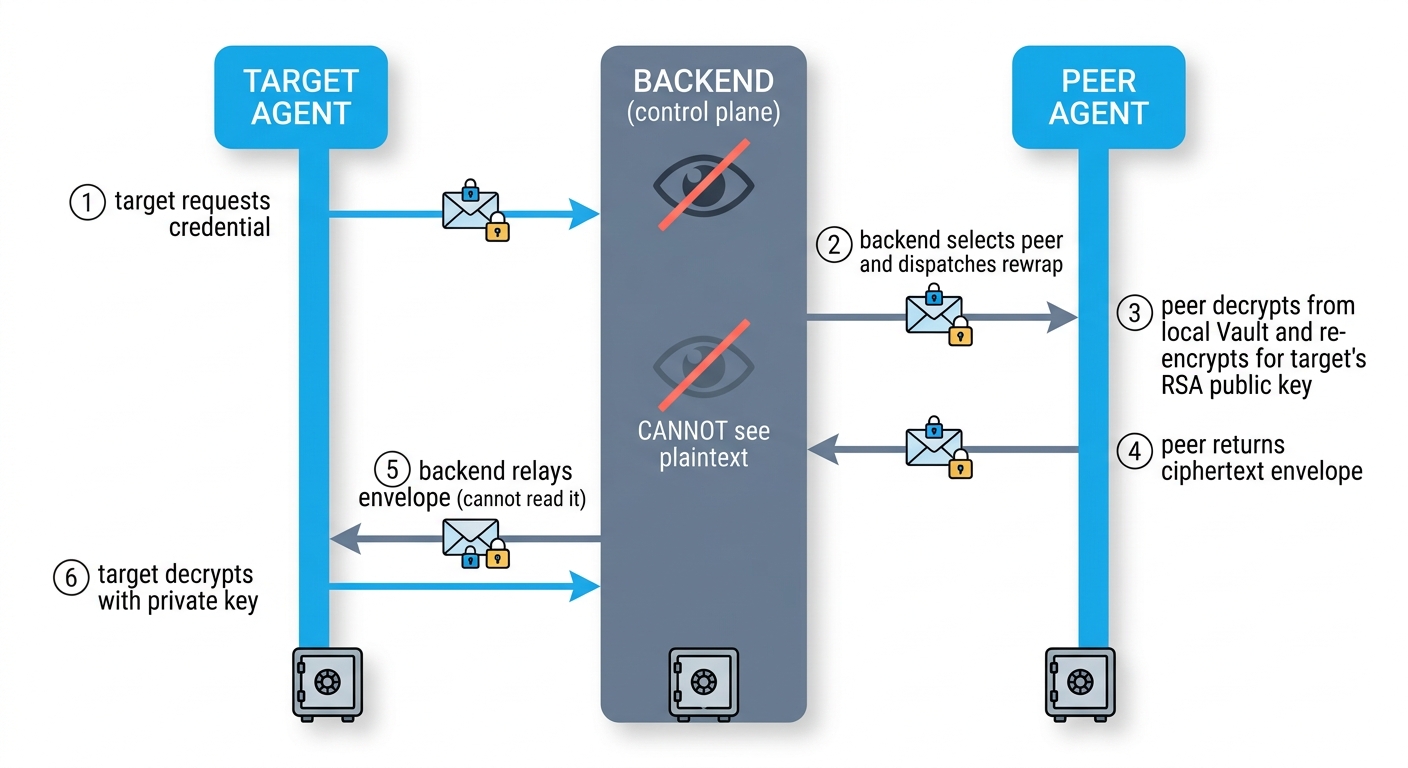
| Role | What it has | What it sees |
|---|---|---|
| Target agent | Its own RSA-2048 private key in local Vault. Missing the credential. | Decrypted plaintext (after RSA-OAEP unwrap + AES-GCM decrypt). |
| Peer agent | Already holds the credential plaintext in its local Vault. RSA-2048 keypair. | Plaintext (briefly, during re-encryption). Target’s public key. |
| Backend (control plane) | Postgres rows, Redis coordination state, WebSocket connections to both agents. | Ciphertext envelope. Commitment digest. UUIDs. Never plaintext. |
The backend’s job is to be a dumb pipe with rules. When the target needs a credential, the backend picks an eligible peer that already has it. The backend tells the peer who to encrypt for (target’s public key). The peer decrypts the credential from its own Vault, re-encrypts it for the target, and hands the ciphertext envelope back to the backend. The backend relays the envelope to the target. The target decrypts using its own private key.
At no point does the backend touch the AES key (it’s RSA-OAEP-wrapped to the target’s public key — only the target’s private key can unwrap it). At no point does the backend see JSON plaintext.
Concretely, here’s the envelope format we use across the platform:
{
encrypted_key: base64( RSA-2048-OAEP-MGF1-SHA256( aes_256_key ) ),
iv: base64( 12-byte random IV ),
ciphertext: base64( AES-256-GCM(plaintext_json) without auth tag ),
tag: base64( 16-byte GCM auth tag )
}
A few specifics worth flagging if you’re a security architect reading this:
- No key derivation. The 32-byte AES key is fresh
os.urandom(32)per envelope. We don’t derive from a shared secret because there is no shared secret between peer and target — the binding goes through the public key. - OAEP padding with MGF1-SHA256 and SHA-256 hash, no label. This matches the browser-side Web Crypto API defaults so envelopes produced anywhere in our system (frontend at credential creation time, peer at rewrap time) are byte-identical in shape.
- Best-effort zeroization. AES key and plaintext are stored in mutable
bytearrays and overwritten with zeros infinallyblocks. Python doesn’t guarantee memory hygiene forbytes/str, only for buffers we can mutate — we acknowledge this as a threat-model limit, not a complete defense. - Crypto library:
cryptography>=43.0.0(thehazmatprimitives —AESGCM,padding.OAEP,serialization.load_pem_*). - Length caps. The backend rejects peer-supplied envelopes where the ciphertext exceeds 128KB or where any field is implausibly long. A hostile peer can’t ship a 1GB blob and force the backend to relay it.
When a peer’s response arrives, the backend validates four bindings before forwarding to the target:
- The WebSocket-authenticated sender matches the expected peer agent ID.
- The credential ID matches the dispatched request.
- The target agent ID matches the dispatched request.
- The envelope shape is well-formed.
A response that fails any of these is recorded in the audit trail as rewrap_response_unsolicited with a typed reason. We call this the quadruple-binding guarantee. It’s a necessary defense — but as we’ll see in a moment, it’s not sufficient.
The Patent: Defending Against Our Own Compromised Backend
Here’s the part a security architect will actually care about.
The attack scenario
The four bindings above defend against a malicious peer — an agent that’s been compromised and is trying to inject something that doesn’t match the request. They don’t defend against a malicious backend. And a malicious backend is exactly the threat model “zero-trust” promises to defend against.
Imagine the backend is compromised. An attacker has shell on the API server, can read and modify rows in Postgres, can intercept and rewrite WebSocket messages between peer and target. Without a commitment scheme, every credential sync is an opportunity to substitute plaintext.
Concretely: an operator stores production-db-password and the backend dispatches a sync to agent-2. The compromised backend swaps the relay payload with a different peer’s envelope — say test-db-password, encrypted to agent-2’s legitimate public key. agent-2 decrypts successfully (the AES-GCM tag validates, the RSA-OAEP unwrap succeeds), stores test-db-password under the row labeled production-db-password, and the next workflow run authenticates with the wrong credential against the production database.
The substitution is invisible to both agents because every cryptographic primitive succeeds. The peer encrypted what it thought was right. The target decrypted what it received. Neither one had any way to know they were talking past each other.
This is the attack our existing zero-trust competitors don’t defend against. Most “zero-trust credential” stories defend against passive eavesdropping (TLS handles that). Active substitution by a compromised relay is a different problem entirely.
The defense — plaintext commitment
At credential creation — at the moment a human or an API caller enters a password into the system, before any encryption happens — we compute and persist a per-credential HMAC commitment.
The schema looks like this:
ALTER TABLE credentials
ADD COLUMN plaintext_commitment BYTEA NULL, -- 32-byte HMAC-SHA256 digest
ADD COLUMN commitment_salt BYTEA NULL, -- 32-byte random HMAC key
ADD COLUMN commitment_version INTEGER NULL,
ADD COLUMN last_commitment_bypass_audit_at TIMESTAMPTZ NULL;
The commitment primitive is straightforward HMAC-SHA-256:
def compute_commitment(plaintext_bytes: bytes, salt: bytes) -> bytes:
if len(salt) != 32:
raise ValueError(f"salt must be exactly 32 bytes (got {len(salt)})")
return hmac.new(bytes(salt), bytes(plaintext_bytes), hashlib.sha256).digest()
The keying material is a 32-byte per-credential random salt, generated at credential creation time. The “what gets HMAC’d” is the canonical UTF-8 bytes of the JSON-serialized secret payload.
Critically: the commitment is computed by the encrypter at creation time, not by the peer at rewrap time. This is the load-bearing detail. If the peer recomputed the commitment, a malicious peer could just compute a commitment for whatever substituted plaintext it wanted to inject — and the backend would happily relay the matching pair. The commitment has to come from the original creator of the credential and travel with it forever, regardless of how many times it gets re-encrypted across agents.
Here’s how target-side verification works:
- The target receives a
credential_storemessage from the backend, which includes the originalcommitment_salt(stored backend-side, so the backend can ship it but cannot forge a matching commitment without the plaintext). - The target decrypts the envelope using its own RSA private key.
- The target recomputes
compute_commitment(plaintext.encode('utf-8'), salt_bytes). - The target sends the recomputed commitment back to the backend in its
credential_storedACK. - The backend compares the target’s recomputed commitment to the stored commitment using
crypto.timingSafeEqual— a constant-time compare that defeats timing-channel side-channels.
If the comparison succeeds, the backend marks the credential delivered. If it fails, things get interesting.
The defense-in-depth response on mismatch
When the target’s recomputed commitment doesn’t match the stored commitment, the backend doesn’t just log it. It treats it as a confirmed integrity attack:
-
Don’t persist. The credential is not marked as delivered. The target’s local Vault may have been polluted with a substituted plaintext, but the backend’s source-of-truth row reflects “not stored.” The target’s task receiver sees
credential_unavailablefor any workflow that tries to use this credential, and refuses to run. -
Source attribution. The backend reads its
pendingStoreDeliveriesmap (populated when the rewrap was dispatched) to recover the source peer’s agent ID. We know which peer encrypted the envelope that turned out to fail commitment. -
Source peer invalidation. The source peer’s own
credential_agentsrow is markedsecret_stored=false, last_error='COMMITMENT_MISMATCH_SOURCE'. That peer is no longer trusted as a source for this specific credential. -
Peer blocklist. The (credential, peer) pair is added to a 24-hour blocklist. Future rewrap dispatches consult the blocklist when picking eligible peers and skip blocklisted ones. Mirrored to Redis as
peerblock:{credId}set membership for cross-replica visibility. -
Critical alert. A
peer_agent_integrity_failurerow is inserted into the alerts table at severitycritical, idempotent viaNOT EXISTSso we don’t duplicate-fire. -
Burst detection. A sliding window of the last 5 minutes of mismatch events for this agent — if it exceeds 10, an
agent_commitment_floodalert fires at severityhigh. Cross-replica via a Redis sorted set so a compromised attacker can’t evade detection by round-robining requests across backend replicas. -
Audit trail. A
commitment_mismatch_detectedrow is written toaudit_trail. The audit trail itself is protected by an immutability trigger that rejectsUPDATEandDELETEregardless of role. -
Caller resolution. Any workflow task that was waiting on this credential is unblocked with a typed
COMMITMENT_MISMATCHfailure — not a silent timeout.
Why this matters
The commitment scheme converts a silent attack (substitution that succeeds cryptographically) into a noisy one (mismatch detection + critical alert + peer blocklist + audit trail). The compromised backend can still cause unavailability — it can refuse to relay, drop messages, time out — but it can no longer forge a successful credential delivery.
In other words: the integrity of the credential store no longer depends on the integrity of the control plane. Even if our cloud is compromised tomorrow morning, your credentials don’t get silently swapped under your nose.
That’s the load-bearing claim in Patent 10 (filed as provisional, April 25, 2026). Most “zero-trust” stories in this market defend against passive eavesdropping. Ours defends against active substitution by our own relay.
When Sync Happens — Three Trigger Paths
Knowing how a sync works is half the story. The other half is when. There are three ways a credential sync gets triggered in Regnor™, plus a fourth admin-driven one. All four flow through the same dispatcher, but they have very different latency profiles and notification policies.
1. New-agent registration backfill
When a new agent registers with the backend, it walks through one of three modes:
first_registration— agent’s first-ever handshake. Backend fans out every credential in the org to it.key_regenerated— existing agent regenerated its RSA keypair (e.g., recovery from corruption). Previously stored Vault entries are now unreadable under the new key, so we re-fan-out everything.warm_reconnect— agent reconnected with a list of credential IDs it already has. We backfill only the gap. Capped at 10,000 known IDs to bound scan cost.
While a backfill is running, the agent’s status flips from online to backfilling. The load balancer treats backfilling as ineligible so workflows don’t land on a half-synced agent. Token-bucket concurrency: 5 simultaneous dispatches per backfill job — high enough to make backfill fast, low enough to not overwhelm peer agents.
2. JIT-repair on credential_unavailable
This is the path that makes the 02:00 reboot scenario work.
Workflow lands on an agent that doesn’t have a credential. The agent’s task receiver fires a credential_missing WebSocket message to the backend. The backend’s handler immediately dispatches a peer rewrap. Latency budget on the success path: error → backend dispatch → peer rewrap → backend relay → target store → ACK ≈ typically under one second on a healthy network.
The agent’s wait timeout is 15 seconds. In practice, JIT-repair finishes in well under a second, so the workflow never even notices it stalled.
Defenses around the JIT path:
- Rate limit: 30 requests/minute per agent. Exceeded → typed
RATE_LIMITEDreply. Defends against a misbehaving agent. - Flood detect: 100 requests in 5 minutes from one agent →
agent_credential_floodalert (severityhigh). Defends against a compromised agent. - Cross-replica flood detect: every event is mirrored to a Redis sorted set so a compromised agent round-robining requests across backend replicas can’t slip under the per-replica threshold.
- Reason whitelist: replies use a small allow-list of public reasons. Internal state (e.g.,
DISPATCH_BACKPRESSURE) is mapped to a public reason (BACKEND_BUSY) so internal architecture doesn’t leak to a potentially compromised agent.
3. Background reconciler sweep
The reconciler runs every 60 seconds and picks up any credentials whose secret_stored = false against an online or backfilling agent. The query is bounded to 100 rows per tick to avoid pathological scan times.
Backoff on retries:
| Attempt | Wait |
|---|---|
| 0 | 30 seconds |
| 1 | 2 minutes |
| 2 | 8 minutes |
| 3 | 30 minutes |
| 4–9 | 2 hours |
| 10+ | retired (MAX_RETRIES_EXCEEDED) |
After 10 failed attempts the row is flagged stalled and a credential_sync_stalled alert fires (deduped at 24 hours). At that point a human operator needs to investigate.
The reconciler also coordinates across replicas via a distributed mutex (Redis SET-NX-EX with 55-second TTL, just shy of the 60-second tick interval) so a 3-replica deployment doesn’t run three concurrent reconciler sweeps.
4. Manual retry
Wired into the admin UI’s per-credential sync chip. Operators can click “Retry” on a stalled credential and force an immediate dispatch. 30-second client-side cooldown prevents accidental hammering.
Multi-Replica Backend Safety
Single-replica systems are easy. The moment you scale horizontally — multiple backend instances behind a load balancer, sharing a single Postgres and Redis — every coordination invariant has to survive replicas not knowing about each other.
The hard problem in our system: replica-1 and replica-2 simultaneously decide to rewrap the same (credentialId, targetAgentId) pair. We want exactly one peer rewrap to actually run, and both replicas’ callers to receive the same outcome.
The solution is a subscribe-first-then-lock pattern:
// Lock key: inflight:{credId}:{targetId} — TTL 60s
// Channel: inflight_result:{credId}:{targetId}
// CRITICAL: subscribe BEFORE the lock check.
unsub = await store.subscribe(channel, payload => subResolve(payload));
gotLock = await store.setIfNotExists(inflightKey, REPLICA_ID, { ttlMs: 60_000 });
if (gotLock) {
// Originator: drop our own subscription so we don't self-fire,
// run dispatch, publish outcome, DEL the inflight key.
await unsub();
outcome = await _runDispatch(...);
await store.publish(channel, outcome);
await store.del(inflightKey);
return outcome;
}
// Subscriber: wait for the originator's outcome.
return await Promise.race([subPromise, timeout(150_000)]);
Why subscribe before locking? If we locked first, an originator on a third replica could publish the outcome between our lock check and our subscribe, and we’d hang for 150 seconds waiting for an event that already fired. The speculative subscribe closes that race. If we end up being the originator, we just unsubscribe before doing the actual work.
The 150-second timeout is calculated as MAX_PEER_ATTEMPTS × PEER_TIMEOUT_MS + 60s = 3 × 30s + 60s — sized to cover a legitimate 3-peer-retry dispatch under degraded Postgres latency without spuriously tripping.
Cross-replica response handling works similarly: a peer’s response can land on any replica, but the originator replica is identified by originating_replica_id in the pending row. If the response lands on a non-originator, that replica validates the bindings, atomically deletes the pending row (CAS via Redis DEL return value — only the replica whose DEL returns truthy proceeds), and publishes to the response channel where the originator’s _runDispatch is awaiting.
The whole coordination layer (rewrapCoordinationStore.js) abstracts over MemoryStore (single-replica development) and RedisStore (multi-replica production). Selection is via the REWRAP_COORDINATION_BACKEND environment variable. Graceful fallback: if Redis is unavailable at startup, the system falls back to MemoryStore and emits a redis_coordination_degraded alert. If Redis fails mid-session, individual operations fall back per-op with the same alert.
This is the kind of detail that doesn’t sell to anyone except SREs and security architects. Both audiences are exactly the people we need to convince.
What Operators See
The full audit and alerting surface is intentionally rich:
| Alert type | Severity | Condition |
|---|---|---|
credential_sync_stalled |
medium | 10 failed attempts AND idle 24h |
agent_credential_flood |
high | >100 missing-credential events in 5 min from one agent |
credential_commitment_mismatch |
critical | Target reported HMAC mismatch |
peer_agent_integrity_failure |
critical | Mismatch attributed to a source peer |
agent_commitment_flood |
high | >10 mismatches in 5 min from one agent |
redis_coordination_degraded |
medium | RedisStore failed >5 min |
The audit trail uses a write-ahead pattern: every dispatch writes a pending row at start and a final row (success, peer_failed, timeout, or exhausted) at completion, linked via dispatch_audit_id. A crash between the two writes leaves the pending row as durable evidence — exactly what you want during a forensic review.
In the UI, operators see a per-credential sync chip showing how many agents have it (✓ 3/3 synced in green, ⚠ 2/3 synced in amber, ⏳ Pending (1) in blue). When a commitment mismatch happens, the chip turns red with an “Integrity failure” badge. Legacy credentials created before the commitment system rolled out get an amber “Unprotected” badge until the operator rotates them — visible at a glance, no hunting through logs.
There’s a coordination status endpoint at GET /api/system/rewrap-coordination-status that shows which backend each replica is on and whether anyone is in degraded mode. Useful during a multi-replica deployment debug session.
Honest Caveats
A few things this article does not claim:
- We don’t do zero-knowledge encryption. Plaintext must be decryptable by the peer to re-encrypt. This is an architectural ceiling, not a roadmap item — homomorphic re-encryption for arbitrary password data isn’t practical with current cryptography.
- The reconciler isn’t auto-started in v1. It exists in code and works in tests, but isn’t wired into bootstrap yet. Single-line addition; deferred to a deploy review pass to avoid surprise side-effects on import.
- The agent-side
credential_unavailablehandler is partially deferred. Backend sends the message; agent doesn’t yet route it through the task receiver to short-circuit the 15-second wait. Correctness is intact (the workflow still fails cleanly), UX is marginally worse than it could be. - No Prometheus metrics in-tree today. Observability is Postgres rows and structured logs. Metrics is a roadmap item.
- “All agents down” isn’t solved by this system. That’s an infrastructure-availability problem, not a credential-sync problem. If you’ve taken every agent in your org offline simultaneously, no credential sync protocol will save you.
The implementation is ahead of the IP filings, which means we filed Patent 10 with full visibility into the production code path — not as a speculative claim ahead of the engineering. This material is publishable as of the brief date.
Frequently Asked Questions
Why HMAC and not a digital signature for the commitment?
HMAC is symmetric and shorter (32 bytes vs. ~256 bytes for an RSA-2048 signature). The commitment doesn’t need to be publicly verifiable — only the target needs to recompute it, and the target gets the salt from the backend. A signature would add overhead without adding security in our specific threat model.
What happens if I rotate a credential?
Rotation is a new credential write. The new plaintext gets a new commitment salt and a new commitment digest. The old credential is marked superseded and stops being a sync target. New peer rewraps for any agents that haven’t received the new version trigger automatically through the same three-trigger system (backfill if the agent registers fresh, JIT if a workflow hits the missing credential, reconciler if it sits stalled).
Can I scope which agents get which credentials?
Yes. The credential’s sync scope can be set to auto_all (default — all agents in the org get it) or explicit (only agents an operator has explicitly granted permission to). High-privilege credentials — root passwords, API tokens for production systems — typically use explicit scope.
What’s the performance impact of all this?
JIT-repair latency is typically under one second end-to-end. New-agent backfill processes 5 credentials concurrently per agent — 1,000 credentials backfill in roughly 2-4 minutes. The reconciler is bounded to 100 rows per tick to keep its worst-case latency predictable. None of these numbers change in single-vs.-multi-replica deployments.
Is the patent-pending status real or marketing?
Provisional Patent Application filed with the USPTO on April 25, 2026. The provisional anchors the priority date and gives us 12 months to convert to a full utility application. The novel claim is the commitment-protected peer-rewrap protocol — substantively, the load-bearing innovation is who computes the commitment (the original encrypter at creation, not the peer at rewrap) and what it binds (plaintext, regardless of how many times it gets re-encrypted). We can discuss the implementation publicly because the priority date is locked.
What This Unlocks
For network operations teams:
- Rolling kernel patches across multiple agents without maintenance windows
- Agent reboots that don’t break workflows
- No single point of failure in the automation runtime
For security teams:
- Plaintext credentials never transit the cloud control plane
- Defense against compromised control plane (HMAC commitment + peer attribution + blocklist + critical alerts)
- Immutable audit trail for every sync — answer “who, when, why” in a single query
- A defensible posture against the regulatory questions auditors ask about cloud-mediated credential storage
For executives:
- Patent-protected differentiation against competitors who force you to pick between zero-trust and HA
- Regulated-industry deployments without the security-team veto that kills cloud-centralized credential systems
- An architectural story that holds up to due diligence
Most network automation platforms in this market force you to pick: cloud-centralized credentials (easy HA, security-team veto) or single-agent on-prem (security-team approval, no HA). The technical answer to “can you have both” turns out to be yes — but it requires a protocol design that defends against the relay itself, not just the parties on either side of it.
We had to write that protocol because nobody else had. We filed Patent 10 because we’d rather not have to write it twice.
Related reading on AutomateNetOps.AI:
- Why On-Premise Matters for Network Automation Security — the broader on-premises security argument that drove this design
- Network Compliance Automation: Stop Checking Configs Manually — Tavrin™ compliance, a downstream beneficiary of the multi-agent architecture
- The First AI-Native Network Automation Platform — the broader Regnor™ architecture this credential-sync design fits into
- Ansible is 14 Years Old. Here’s What’s Actually Broken About It. — why we built a new architecture from scratch instead of layering on Ansible
Regnor™ is in beta today. If your organization has been telling you “we love zero-trust or we love HA, pick one,” we’d love to show you the version where you don’t have to.
Tags: credential-sync, hashicorp-vault, multi-agent, network-automation, network-security, patent, regnor, zero-downtime, zero-knowledge, zero-trust
Categories: Network Automation, Security
Updated:
You may also enjoy
Three accreted pains retired: storage amplification, bolt-on attachments, and WAN re-pull. The Regnor™ unified document system is one fabric — content-addres...
How Regnor™ Topology lets you query your network in plain English and rewind it through time — built so the LLM never touches your database and the past is h...
About Me


Ready to Automate?
See how AutomateNetOps.AI can transform your network operations with zero-trust security.