Ansible is 14 Years Old. Here’s What’s Actually Broken About It.
In November 2025, Ansible release 12 shipped with a quiet, catastrophic bug: the network device configuration modules stopped accepting Jinja2 templates as input. The documentation still told you to use templates. The modules silently didn’t. Four releases later — as of December 2025 — the bug was still there.
Ivan Pepelnjak, one of the most respected voices in network automation, wrote a post titled “Ansible Abandoned Network Automation.” netlab — a widely-used network lab toolkit — pulled Ansible out of its configuration pipeline entirely. Red Hat’s public response, according to Pepelnjak, was essentially “we’ll agree to disagree.”
This isn’t one bug. This is what 14 years of accumulated architectural debt looks like when the original design assumption — that all automation targets are Linux servers — never got updated. Network devices are not servers. Ansible was built in 2012 for a world where everything you’d automate had SSH, a shell, and a package manager. Your routers don’t. Your firewalls don’t. Your switches really don’t.
Let’s talk about what’s actually broken — with specific receipts. And then let’s talk about what comes next, which isn’t what you probably expect.
Credit Where It’s Due
Before the critique: Ansible changed the world. That’s not hyperbole.
In 2012, the state of the art for configuration management was Puppet and Chef — both agent-based, both requiring you to deploy and maintain a Ruby runtime on every target. Ansible’s agentless SSH-push model was a real innovation. It said: “If you can SSH into a box, you can automate it.” For servers, this was liberating.
The other thing Ansible got right: YAML playbooks were genuinely more readable than bash scripts. Five years later, that might feel like damning with faint praise. In 2012, it was transformational.
And the module ecosystem grew. Ten thousand modules covering every cloud provider, every Linux distribution, every major SaaS. For server-side sysadmins, Ansible democratized automation in a way that no product before or since has quite matched.
So this isn’t a hit piece. Ansible is a foundational tool, and a lot of network engineers still use it productively. The argument isn’t that Ansible is bad. The argument is that Ansible was built for a different problem, and 14 years of community contributions haven’t patched the architectural impedance mismatch with network devices.
Here’s what that mismatch actually looks like in 2026.
The 5 Things Network Engineers Actually Complain About
1. “It was built for servers, and you can tell.”
Ansible’s execution model is SSH-push: open an SSH connection to the target, copy a Python module to /tmp, execute it, parse the JSON result. This works beautifully on Linux servers. It works passably on some network operating systems. It breaks in subtle, specific ways on others.
Modern network devices expose structured management APIs: NETCONF (YANG models, transactional changes), gNMI (gRPC-based streaming telemetry and config), RESTCONF (REST over YANG). These protocols were designed precisely because SSH CLI screen-scraping is fragile. Cisco IOS-XE, Junos, Arista EOS, Nokia SR OS — they all ship with at least one of these today. Ansible’s network collections technically support some of them, but the abstractions leak constantly. Most operators default back to the SSH cli_command / cli_config modules because they’re the least surprising.
Then there’s idempotency. Ansible’s server modules guarantee idempotency: run the same playbook twice, get the same end state. Network modules approximate it. Pepelnjak wrote a detailed post in 2020 about spending an hour debugging why his Nexus OS config wouldn’t apply, only to discover that the interface X stanza cannot appear twice in the configuration you push. His exact words:
“Can’t tell you how much I hate Ansible’s lame attempts to do idempotent device configuration changes.”
That bug eventually got patched. But the underlying problem — that Ansible treats network config like a text file, not a hierarchical tree — hasn’t changed.
2. “Templating that works, then doesn’t, then does again.”
Variable precedence in Ansible is famously a maze. The docs list 22 different sources where a variable can be defined, in a carefully-prioritized order. -e extra vars are supposed to win. Except, as Pepelnjak documented in a January 2024 post, there are plenty of cases where set_fact in a prior task overrides the extra var you thought would win.
Multi-line Jinja2 expressions in YAML? Pepelnjak tested them and concluded: “works every time 50% of the time.” The behavior depends on your Ansible version, your YAML literal-vs-folded block marker, and whether your expression happens to trigger a corner case in the parser.
Loops? Ansible may silently reorder list values. Pepelnjak’s example was BGP configuration: if you deploy mpls configuration before bgp, you get broken LSPs. If Ansible decides to reorder your loop, your deployment is corrupt. He discovered this the hard way.
None of these are conspiracy theories. They’re single-maintainer GitHub issues documented over a decade. Each one took hours of someone’s life to diagnose, and most of them recur in new forms with every major Ansible release.
3. “Collections that are abandonware.”
Ansible’s modularity is an advantage — until it isn’t. Much of the network automation functionality lives in collections maintained by vendors or community volunteers. When those maintainers lose interest, the collections rot.
Nokia’s ansible-networking-collections repository — which includes the SR OS collection that netlab and many real operators depend on — was last updated four years ago (as of this writing). Open GitHub issues from 2020 sit unaddressed. An issue from 2023 literally titled “Please Update the Collection” notes that the collection hasn’t been touched in three years.
This isn’t unique to Nokia. Scan the ansible-collections GitHub org and you’ll find network collections with years-old open PRs, broken CI, and one or two overstretched maintainers. The model — “anyone can publish a collection, and the community figures out maintenance” — works great for servers (where Red Hat and a large commercial ecosystem fund the core collections) and less well for network gear (where vendors don’t see Ansible as strategic and volunteers burn out).
4. “Deprecations without migration paths.”
Ansible release 12 (November 2025) broke the src parameter of most network config modules. The src parameter — which let you pass a Jinja2 template path to be rendered and applied to the device — was the canonical way to push templated configs. Four releases of Ansible shipped with this broken before anyone noticed.
The fix, PR #743, was merged in January 2026. It restored backward compatibility. But it also added a deprecation notice: as of January 2028, src will stop processing templates and only accept plain config files.
The GitHub issue documenting the concern is stark:
“Unless I’m missing something, changing the behavior of the ‘src’ parameter to accept only plain configuration files would force a complex workaround for configuration templating: Get a unique local file name; Create a local rendering of the configuration template; Use local file name in
_something_configcall; Remove the local file.”
A one-line operation becomes a four-step dance. And this isn’t a theoretical concern — templating configs is the entire reason most network engineers adopted Ansible in the first place. The deprecation path is an ergonomic downgrade, justified by internal refactoring that prioritizes server-side sensibilities.
The deeper signal isn’t that one deprecation hurts. It’s that networking use cases aren’t driving Ansible’s roadmap. They’re bending to it.
5. “No real workflow engine — playbooks are linear.”
An Ansible playbook is a sequential list of tasks. You can branch with when: conditionals, loop with with_items, trap errors with block/rescue/always. These are language features, not a workflow model.
A real workflow engine gives you:
- Graph-based execution — nodes with multiple inputs, outputs, and branching edges
- First-class approval gates — “stop here until a human signs off”
- Native parallelism with structured fan-out / fan-in
- Event-driven triggers — “run this when a SNMP trap fires, not on a schedule”
- Compensation / rollback paths — “if step 5 fails, run steps A and B to undo steps 1–4”
- Per-device, per-step observability — structured execution records, not stdout dumps
- Execution revisions pinned to specific playbook versions for audit
Ansible has none of these as first-class constructs. The community workarounds — AWX workflows, Ansible Tower job templates, custom callback plugins, rolling your own event engine — exist precisely because the base product doesn’t meet this bar. And AWX’s workflow UI, to put it charitably, shows its age.
This matters more than any single bug. Because once your automation crosses the boundary from “apply a config change” into “orchestrate a multi-step process involving approvals, conditional branches, external systems, rollback logic, and compliance evidence” — Ansible stops being the platform and starts being one tool in someone else’s platform.
That someone else’s platform is usually a homegrown combination of Python, Bash, Jenkins, and tribal knowledge. Every network team has one. And every network team eventually loses the one person who knows how it works.
The Real Cost of Staying
Tool age isn’t automatically bad. Linux is older than Ansible. PostgreSQL is older than Ansible. Vim is much older than Ansible. The issue isn’t the calendar.
The issue is 14 years of scar tissue accumulating around an architectural ceiling.
Every year Ansible ages, the friction of keeping it in production grows:
- New hires don’t want to learn it. Engineers joining a network team in 2026 grew up on APIs, not YAML. They expect structured data, not stdout parsing. They want to
curla RESTCONF endpoint, not debug why their Jinja2 filter works on Linux but breaks on Nexus. - Commercial vendors are shifting their integration focus. New network OS platforms are shipping with API-first management (gNMI, RESTCONF) and treating Ansible as a legacy integration, not a primary surface. Watch the release notes for Cisco IOS-XE, Arista EOS, Nokia SR Linux — the new features land in gNMI first, Ansible last.
- Your playbooks become a liability. The longer you run Ansible, the more playbooks you have. Each one was written by someone with implicit assumptions. Migrating them is a project. Not migrating them means living with compounding drift.
- The “one person who knows how it works” is a real risk. Every team has a hero who knows where all the
group_varslive, which variables have unexpected precedence, and which collections are safe to upgrade. When they leave, the institutional knowledge goes with them.
None of this means “rip out Ansible tomorrow.” That would be reckless. What it means is that the next automation decision shouldn’t extend your Ansible investment — it should start composing it into something bigger.
Which brings us to the actual interesting question.
The Post-Playbook Era Isn’t About Replacing Ansible
Here’s where most “Ansible is dead” essays go wrong: they assume the answer is to replace Ansible.
It isn’t. Your Ansible playbooks work. Your team knows them. Your vault-encrypted variables already exist. Your roles, your collections, your muscle memory — all of that is real investment. Replacing it costs you months and teaches you nothing new about your network.
The actual shift is that Ansible stops being your automation platform and starts being one node in a larger workflow engine.
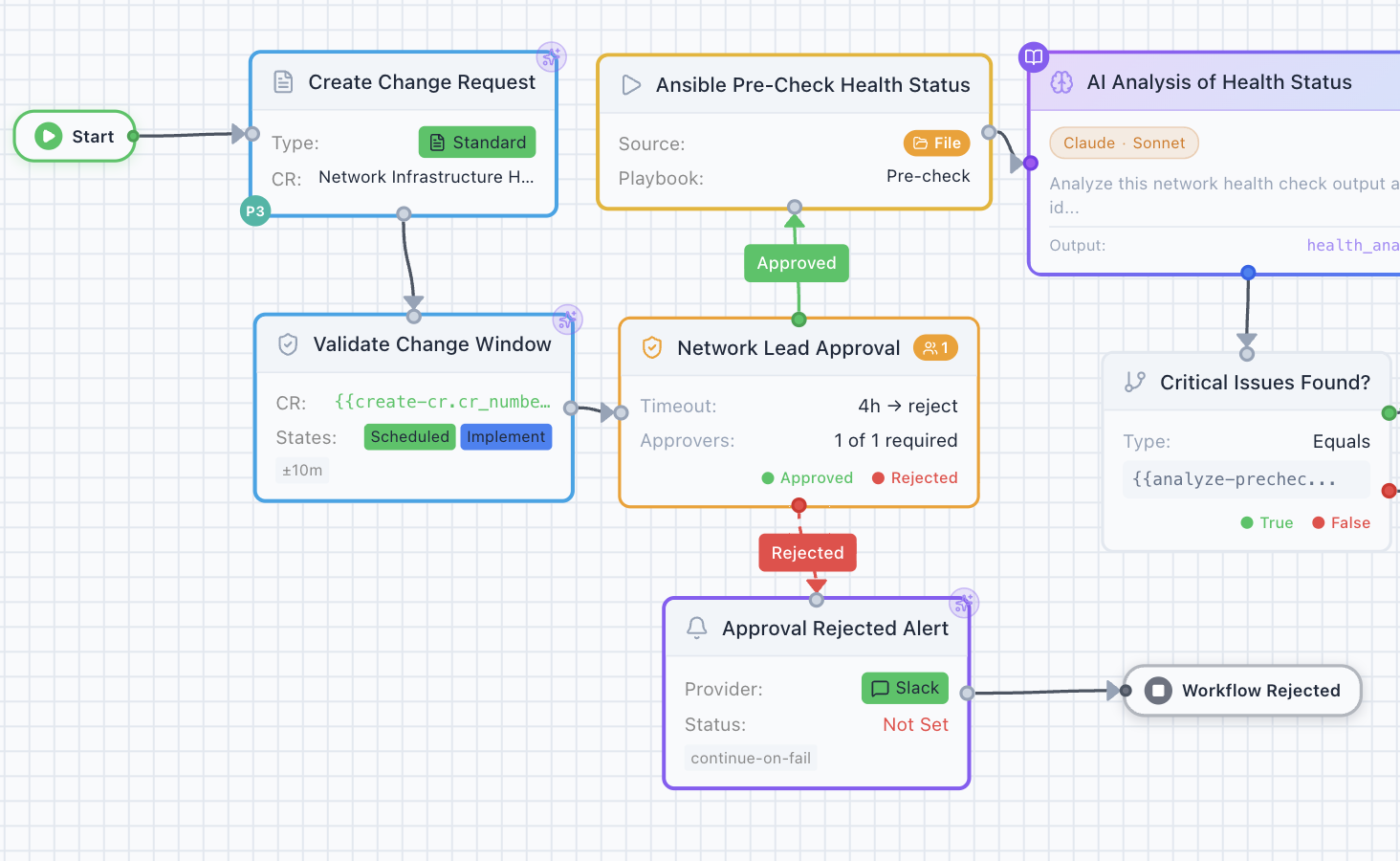
Look at what’s happening in the workflow above. The Ansible playbook isn’t carrying the entire change. It’s flanked by a ServiceNow change-request node, a change-window validator, a human approval gate, and an AI analysis step — and the result of the playbook flows into a critical-issues decision that branches the rest of the workflow. The Ansible node does what Ansible does well (executes a pre-check playbook against the target devices). Everything around it does what Ansible was never designed to do.
This is the design direction we’re building toward in Regnor™, the platform behind Tavrin™ compliance. It’s worth walking through how the Regnor™ Ansible node actually works, because it illustrates what “post-playbook” means in practice — and because every claim below is grounded in shipped code, not a roadmap deck.
Your playbooks, pinned to a commit SHA
In Regnor’s Ansible node, you have three ways to supply a playbook:
- Inline — paste YAML right into the workflow (for quick prototypes)
- File path — point at a playbook on the on-premise agent’s filesystem, under an allowlisted root
- Gitea — repo URL + 40-character commit SHA + path to the playbook
The Gitea mode is the production pattern. When you author the workflow, you pin a specific commit SHA. A playbook edit after that point does not silently change your scheduled workflow’s behavior. The agent caches each (repo, commit) pair content-addressed, so previously-fetched SHAs survive a Gitea outage. You get version-controlled automation with cryptographic provenance — not “whatever was on master when cron last ran.”
This is what Ansible Tower doesn’t give you, and it’s the single biggest operational win for compliance-oriented organizations.
Credentials that never touch disk
When the Ansible node executes on the on-premise agent, it needs to materialize an inventory file and a vault password for ansible-runner. Both are written to tmpfs (/dev/shm, RAM-backed) with mode 0600. When the run ends, the files evaporate — there’s nothing on disk to shred.
On systems without tmpfs, the agent falls back to a disk-based temp directory and explicitly shreds the files (3-pass zero overwrite + fsync) before removing them. The vault password file is opened with O_WRONLY | O_CREAT | O_EXCL to defeat planted-symlink attacks. The subprocess environment is scrubbed before launch — VAULT_TOKEN, AWS_*, GCP_*, and anything matching *_TOKEN / *_SECRET are stripped so a malicious playbook can’t exfiltrate them via lookup('env', 'VAULT_TOKEN').
None of this is possible with ansible-playbook on a laptop or even Ansible Tower — it requires a runtime layer that owns the subprocess lifecycle.
A pre-flight scanner that understands network-specific risk
Before any playbook runs, Regnor’s static analyzer walks the YAML (recursing into block/rescue/always, import_playbook, include_role, and import_role chains) and blocks seven classes of dangerous pattern:
shell:/command:/raw:/script:modules with untrusted input- Jinja2 expressions inside sensitive module arguments
- Execution-override keys in
host_vars(e.g.,ansible_python_interpreter: /tmp/backdoor) extra_varsinjection of dangerous values- Local delegation (
delegate_to: localhost,connection: local) - Template includes with unresolvable Jinja paths
- IMDS SSRF via
uri:against169.254.169.254
Overriding a block requires a separate RBAC permission (ansible:execute_privileged) distinct from general workflow execution. Local delegation requires a different permission (ansible:execute_local_delegation) with no default role binding — it must be explicitly granted per user or role. Every blocked run emits an audit event, so attempted bypasses leave a permanent record.
Ansible Tower’s model — “if you have job template access, you can run any playbook” — doesn’t have this kind of gradient.
Per-task events streamed to the frontend
When a Regnor™ Ansible workflow runs, every runner_on_start / runner_on_ok / runner_on_failed event gets deduplicated by task name, scrubbed for credential patterns, and streamed over WebSocket to the workflow canvas. Operators watch tasks transition from “running” to “ok” in real time, with per-device status dots. No stdout dumps. No refreshing a log page. Structured events, rendered as structured events.
A two-level output envelope for downstream branching
The Ansible node’s output is structured: a top-level summary object (total devices, changed count, failed count), a devices map (per-device counts, task list, facts, diff), and convenience arrays changed_devices / failed_devices for direct branching. Downstream nodes can filter on failed_devices and trigger remediation workflows without path traversal.
This is the same envelope shape our compliance_validation node uses — consistent patterns across multi-device nodes.
WORM compliance evidence
Every Ansible execution writes an immutable row to ansible_execution_evidence with the playbook SHA, resolved collection versions, ansible-core version, device counts, and whether the run used privileged overrides. Database-level triggers reject UPDATE and DELETE regardless of role. Retention floor is 90 days (SOC 2 / ISO 27001), ceiling is 7 years (SOX / HIPAA). When an auditor asks “which version of this playbook ran against router-37 on March 14th?”, you answer with a single query — not a git archaeology expedition.
What this adds up to
Regnor™ doesn’t replace Ansible. It composes Ansible. Your playbooks, your roles, your vault vars, your collections — all still valid. What changes is the execution context: version-controlled pinning, tmpfs credential isolation, a static scanner gate, structured event streaming, and immutable audit evidence. The things Ansible was never built to provide — because it was built for a world where the target is a Linux server and the operator is a sysadmin on the same LAN.
This isn’t the only way to solve the problem. Itential does it differently. Nornir-UI approaches it from a different angle. The point isn’t that our approach is the only answer. The point is that the answer isn’t “give up Ansible” — it’s “stop expecting Ansible to do what it was never designed to do.”
Frequently Asked Questions
Is Ansible going away?
No. Ansible has a massive installed base, a healthy community, and Red Hat’s continued investment in Ansible Automation Platform. What’s shifting is its role: from “the platform” to “one execution engine inside a larger workflow platform.” Expect Ansible to remain the dominant way to actually talk to servers (and some network gear) for many years.
Is Terraform a better alternative for network automation?
For cloud-provisioned network resources (AWS VPCs, Azure Virtual Networks, GCP networking) — yes, Terraform is the right tool. For on-premises network device configuration (switches, routers, firewalls), Terraform’s state-driven model maps poorly to devices that already have existing configurations and running-config drift. You end up fighting the tool. This is why most teams that tried “Terraform for the network” wound up back on Ansible or a purpose-built platform.
What are the real alternatives to Ansible for network automation in 2026?
The honest list: Nornir (Python-native, code-first), Itential (enterprise workflow platform), StackStorm (event-driven automation), custom Python with Netmiko / NAPALM / Scrapli, and newer platforms like Regnor™ that compose Ansible into a visual workflow engine. Each has tradeoffs. The “right” answer depends on your team’s Python comfort level, your compliance requirements, and whether you need a GUI for non-engineer stakeholders.
If my Ansible playbooks work today, should I migrate?
Not as a migration project. Migrate as part of new automation. When your next workflow adds compliance checking, approval gates, structured audit evidence, or multi-vendor integration, that’s the moment to evaluate whether you’re still best served by Ansible alone — or by a platform that runs Ansible as one node. Don’t rewrite what works.
What’s the biggest mistake network teams make with Ansible?
Treating it as a platform instead of a tool. Ansible is phenomenal at executing individual tasks against targets. It’s mediocre as a workflow engine, a compliance system, an observability platform, or an approval-gate engine — and it was never designed to be any of those things. When you hit those needs, don’t bend Ansible to fit. Compose it into something that does.
What Comes Next
If you’ve been nodding along to the specific complaints in this article — the templating bugs, the abandonware collections, the deprecation tax, the missing workflow primitives — you’re not alone. These are well-documented pains with receipts from respected voices in the community. Ansible didn’t fail; it succeeded so well that it outgrew its own design assumptions.
The interesting question isn’t “what do I replace Ansible with?” It’s “what platform lets me keep what’s working and add what isn’t?”
Related reading on AutomateNetOps.AI:
- From Ansible Playbooks to Visual Workflows: A Migration Guide — the practical playbook-by-playbook migration path
- Network Compliance Automation: Stop Checking Configs Manually — where Tavrin™ fits
- AI-Native Network Automation Platform — the Regnor™ platform overview
Regnor™ is in beta today. If you’ve got an Ansible codebase you’re tired of fighting with — and a compliance, audit, or workflow need that Ansible was never built to handle — we’d love to show you what composing Ansible (instead of replacing it) looks like.
Tags: ansible, ansible-alternatives, netops, network-automation, regnor, tavrin
Categories: Ansible, Network Automation
Updated:
You may also enjoy
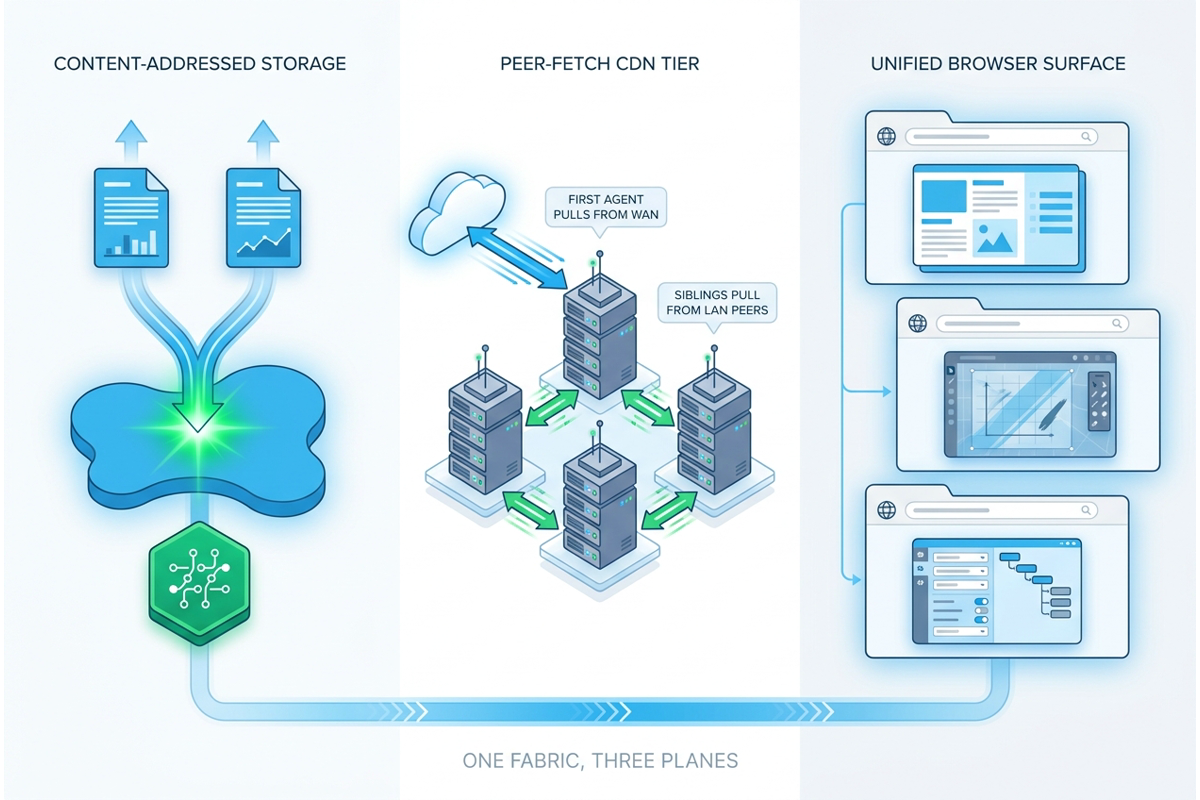
Three accreted pains retired: storage amplification, bolt-on attachments, and WAN re-pull. The Regnor™ unified document system is one fabric — content-addres...
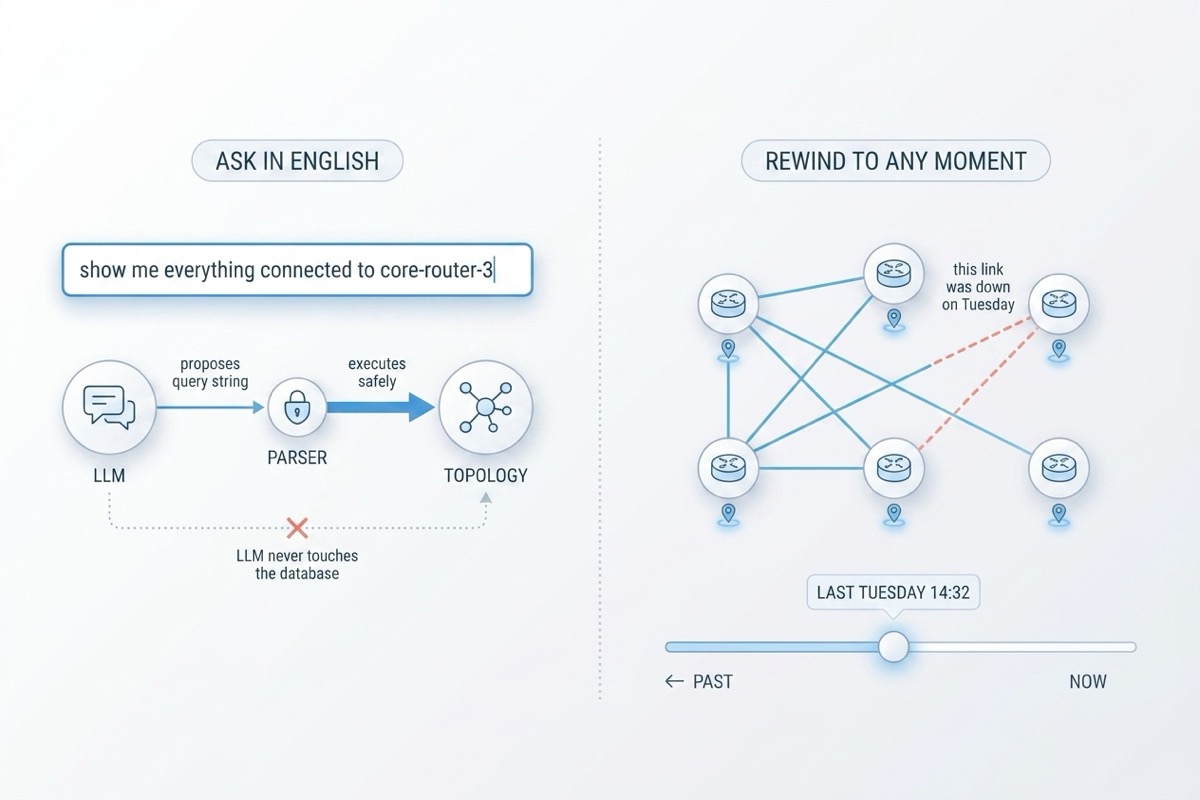
How Regnor™ Topology lets you query your network in plain English and rewind it through time — built so the LLM never touches your database and the past is h...
About Me


Ready to Automate?
See how AutomateNetOps.AI can transform your network operations with zero-trust security.